Pose Constraints for Self-supervised Monocular Depth and Ego-Motion
Enforcing pose network to be consistent improves depth consistency

Consistent Depth without any post-processing. KITTI dataset1
Very well written and clearly structured paper, well done.
- Reviewer 4
Abstract
Self-supervised monocular depth estimation approaches suffer not only from scale ambiguity but also infer temporally inconsistent depth maps w.r.t. scale.
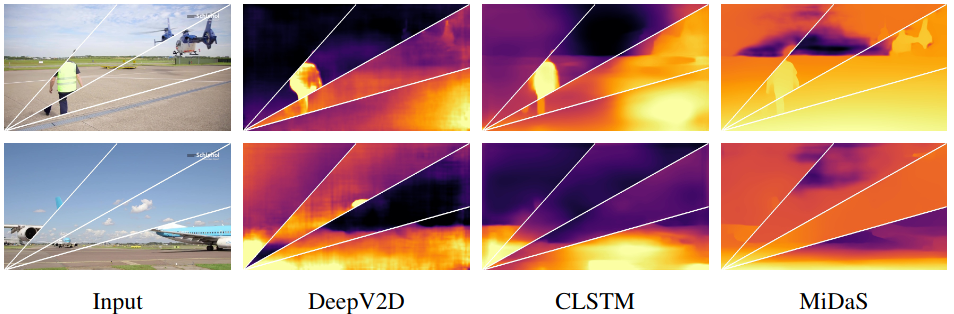
Two depth estimation results on four frames showing the inconsistency problem in existing MDE methods. Image taken from Li et. al.2
While disambiguating scale during training is not possible without some kind of ground truth supervision, having scale consistent depth predictions would make it possible to calculate scale once during inference as a post-processing step and use it over-time. With this as a goal, a set of temporal consistency losses that minimize pose inconsistencies over time are introduced. Evaluations show that introducing these constraints not only reduces depth inconsistencies but also improves the baseline performance of depth and ego-motion prediction.
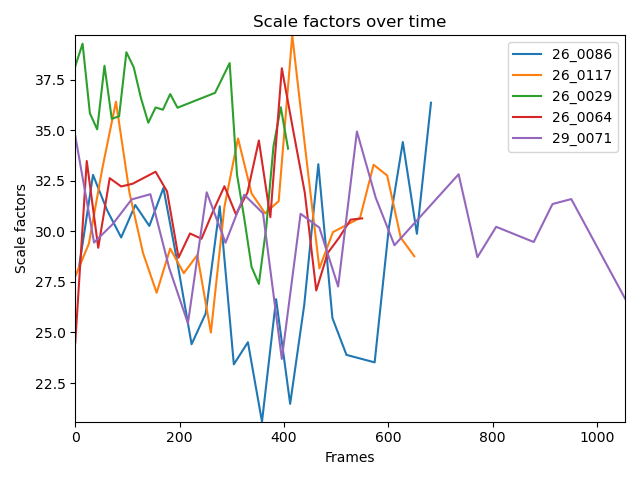
Scale factors () within each KITTI sequences are highly varying
Introduction
For an introduction to self-supervised monocular depth estimation, checkout my previous blog post on Self-supervised Monocular Depth Estimation
BibTeX
@InProceedings{10.1007/978-3-031-31438-4_23,
author="Suri, Zeeshan Khan",
editor="Gade, Rikke and Felsberg, Michael and K{\"a}m{\"a}r{\"a}inen, Joni-Kristian",
title="Pose Constraints for Consistent Self-supervised Monocular Depth and Ego-Motion",
booktitle="Image Analysis",
year="2023",
publisher="Springer Nature Switzerland",
address="Cham",
pages="340--353",
isbn="978-3-031-31438-4",
doi={10.1007/978-3-031-31438-4_23}
}
References:
-
A Geiger, P Lenz, C Stiller, and R Urtasun. 2013. Vision meets robotics: The KITTI dataset. Int. J. Rob. Res. 32, 11 (September 2013), 1231–1237. https://doi.org/10.1177/0278364913491297 ↩
-
Li, S., Luo, Y., Zhu, Y., Zhao, X., Li, Y., Shan, Y.: Enforcing temporal consistency in video depth estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. pp. 1145–1154 (October 2021) ↩